Новое видео
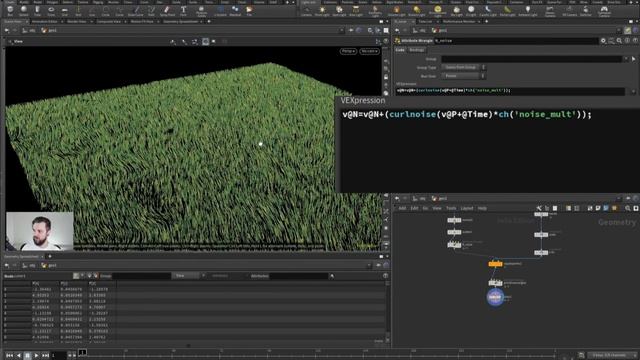
Обзор бенчмарков LLM
Видео: Обзор бенчмарков LLM
Бенчмарк LLM моделей на русском языке Как оцениваются LLM Большие языковые модели? 00:00 - Введение и мотивация для рассмотрения бенчмарков LLM 00:38 - Бенчмарк HumanEval для синтеза кода 02:27 - Изучение набора данных HumanEval 03:24 - Бенчмарк MMLU Массовое многозадачное языковое понимание 04:37 - Изучение набора данных MMLU 05:58 - Мета-бенчмарк BigBench с более чем 200 заданиями 06:50 - Изучение задачи на логическое рассуждение в BigBench 08:13 - Подмножество сложных задач BigBench Hard для LLM 08:46 - Примеры задач из BigBench Hard 10:21 - Завершение и другие важные бенчмарки которые не были рассмотрены,
Комментарии ( 0
)
Сначала новые
Сначала старые
Сначала лучшие
Загружено по ссылке
Присоединяйтесь к обсуждению
М
Гость
ее иза торта вывели, якобы стиль игры очень меняется после черепахи, потому и поставили аллигатора который по факту та же самая черепаха
М
Гость
М
Гость
М
Гость
Текст песни немного хромает, но ритм музыки это вуалирует...Если честно, смотрела не отрываясь... В целом, прикольно..Пародия удалась, правда, я наверное, отстала от жизни и не видела оригинала....Тот, кто знает пред историю, поймет сразу... Mне ролик понравился как развлечение, в принципе, поста...


2026-04-21 в 01:48:27

2025-04-26 в 18:17:04